# Multi-Language Topic Modeling AI Blueprint - deprecated from 11/2024
# Batch-Predict
Topic modeling uses a trained model to analyze and classify textual data in multiple languages and organize similar words and phrases over a set of paragraphs or documents to identify related text chunks or topics. The model can also be trained to determine whether text is relevant to the identified topics. Topic modeling models scan large amounts of text, locate word and phrase patterns, and cluster similar words, related expressions, and abstract topics that best represent the textual data.
# Purpose
Use this batch blueprint to run a trained model that generates a series of topics on custom multi-language textual data, divided by paragraph. The blueprint can be run with either your custom data or a random sample of Wikipedia articles as the training data. To use this blueprint to run the model with your data, provide one super multi_lang_modeling folder in the S3 Connector, which stores the training file containing the text to be decomposed (modeled).
To run a topic model in batch mode on a single-language dataset, see Topic Model Batch. For more information on training a topic-predictor model with custom multi-language data, see this counterpart’s training blueprint.
# Deep Dive
The following flow diagram illustrates this batch-predict blueprint’s pipeline:
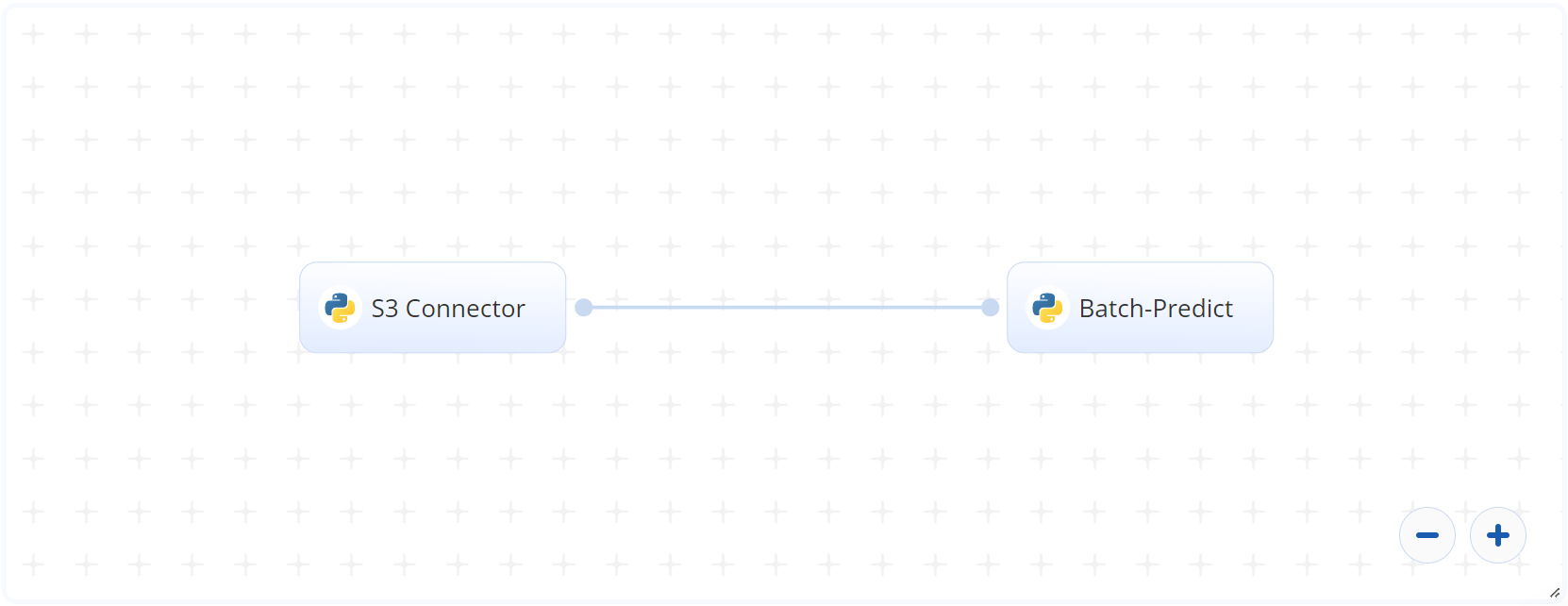
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, the user uploads the CSV file containing custom text stored row-wise within the file.
- In the Batch-Predict task, the user provides locations and values for
--input_file,--model_file,--topic_word_cnt,dictionary_path, andmodel_results_path. - The blueprint outputs a single CSV file with the topics and their probabilities of custom text fitting to them.
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# Inputs
--input_fileis the S3 path to the directory that stores the files requiring decomposition.--model_fileis the S3 path to the pretrained LDA model.--topic_word_cntis the count of words in each topic. Default:5.--dictionary_pathis the S3 path to the saved tf-idf dictionary object.--model_results_pathis the S3 path to the results file that contains the number of topics (to be fed to the model) and their respective coherence scores.
# Outputs
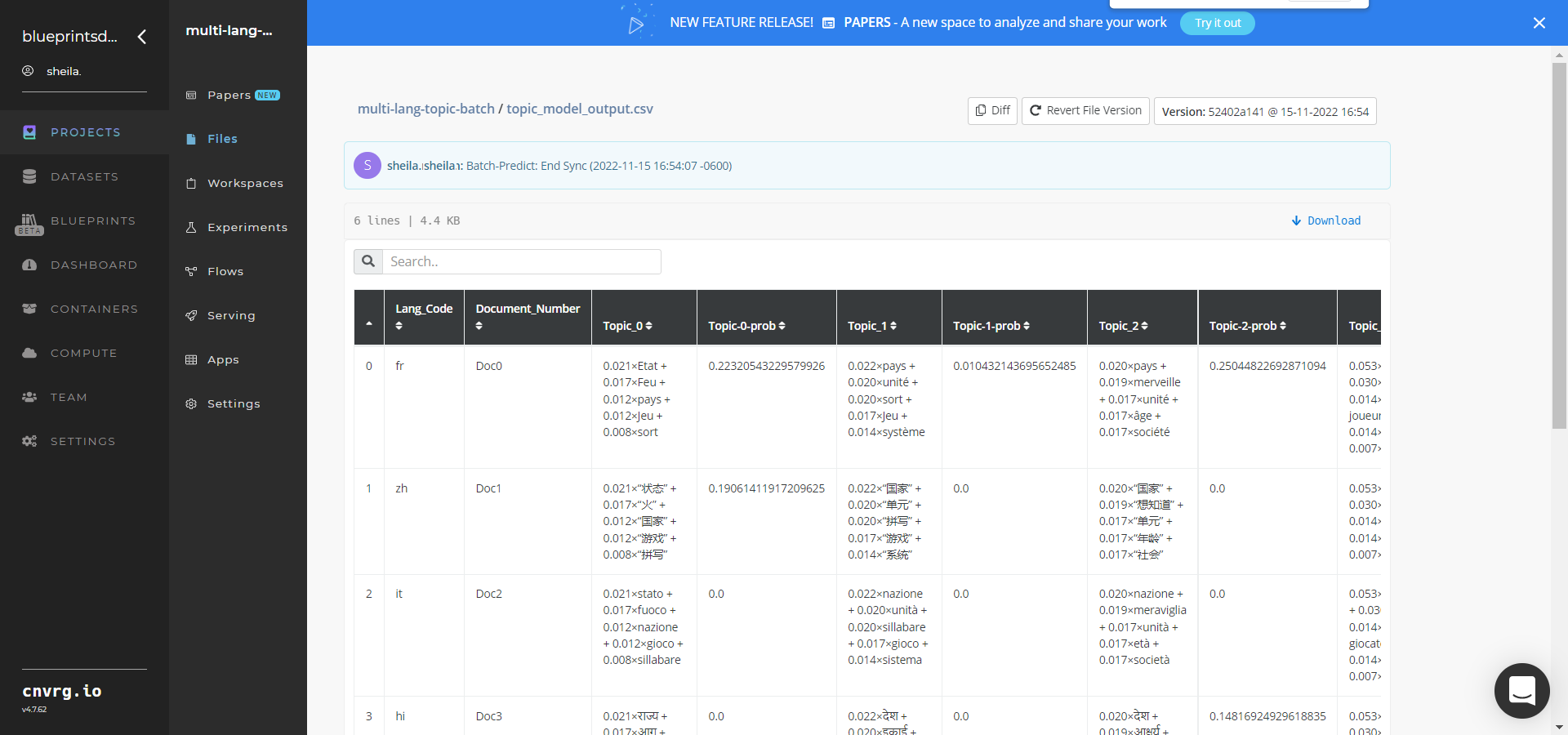
--topic_model_output.csvis the file that contains the mapping of each topic count (such as 6,7,10) with a coherence score. The output is sorted so the top count of topics is the one having the highest coherence score.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to run the topic-modeler blueprint in batch mode:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
Click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value information:
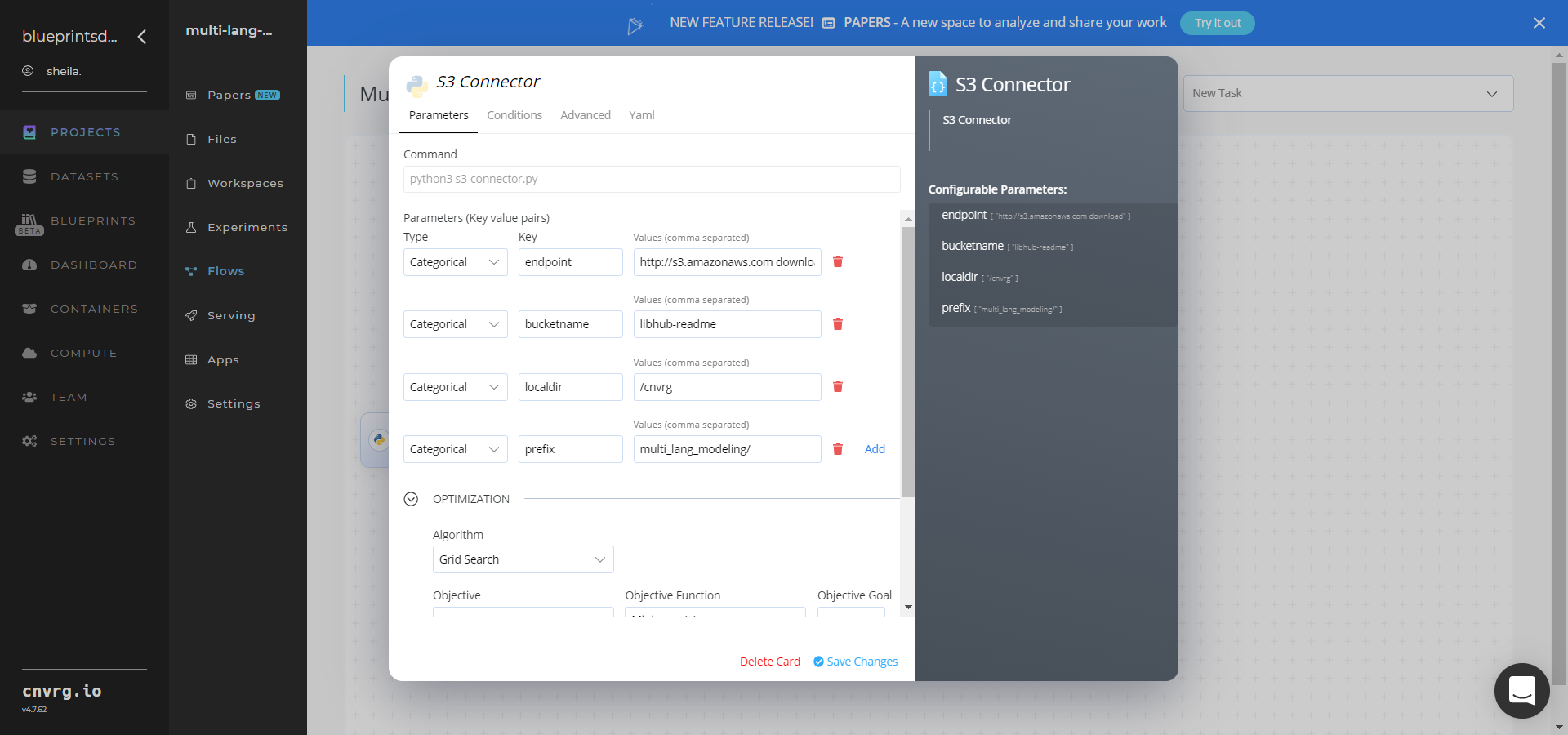
- Key:
bucketname− Value: provide the data bucket name - Key:
prefix− Value: provide the main path to the documents folders
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value information:
Click the Batch-Predict task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
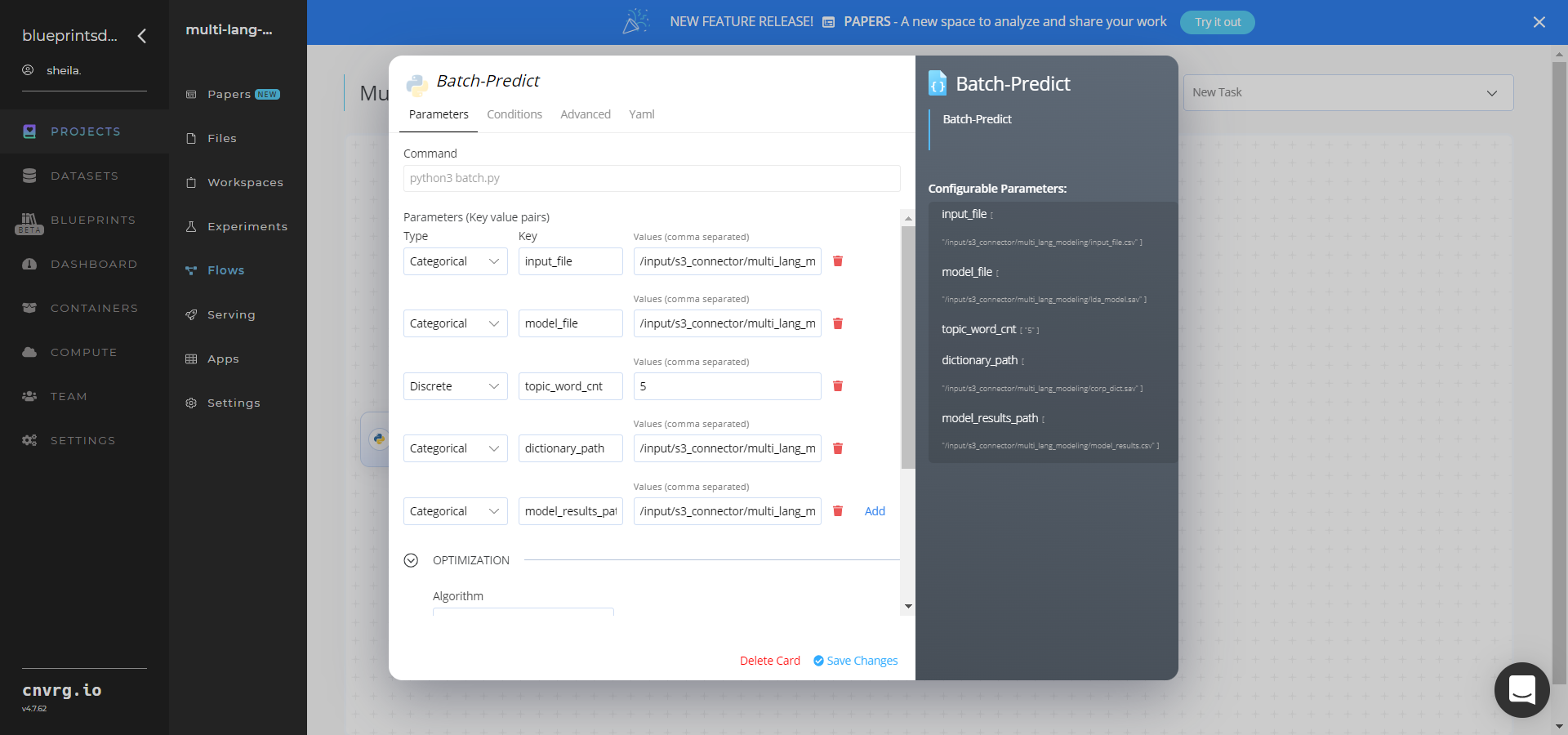
- Key:
--input_file− Value: provide the S3 path to the directory storing the CSV file requiring textual decomposition in the following format:/input/s3_connector/multi_lang_modeling/input_file.csv - Key:
--model_file− Value: provide the S3 path containing the pretrained LDA model in the following format:/input/s3_connector/multi_lang_modeling/lda_model.sav - Key:
--topic_word_cnt− Value: enter the count of words in each topic - Key:
--dictionary_path− Value: provide the S3 path to the saved tf-idf dictionary object - Key:
--model_results_path− Value: provide the S3 path to the results file
NOTE
You can use the prebuilt data example paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
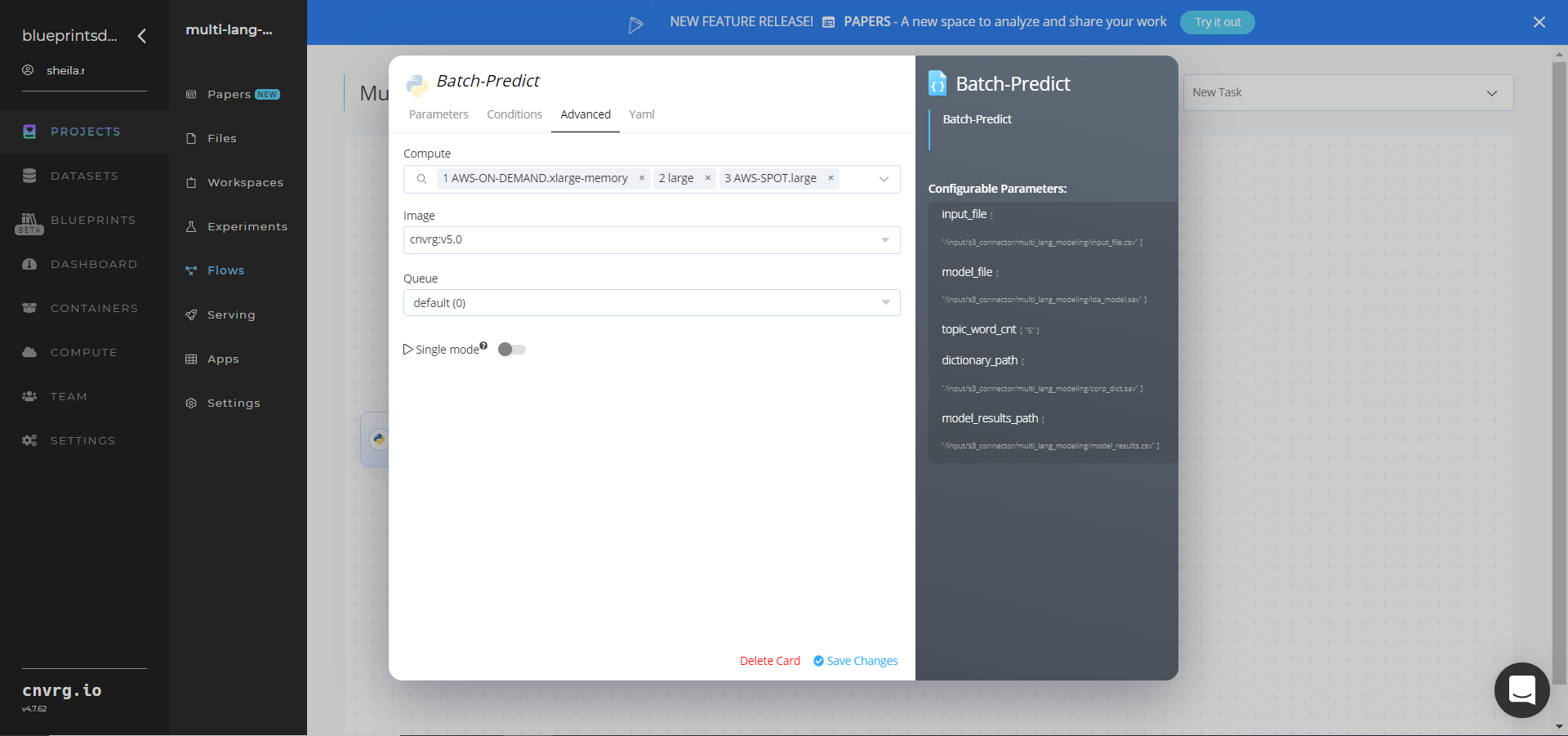
Click the Run button.

The cnvrg software deploys a topic-modeling model that predicts topics from custom multi-language textual data.
Track the blueprint’s real-time progress in its Experiments page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
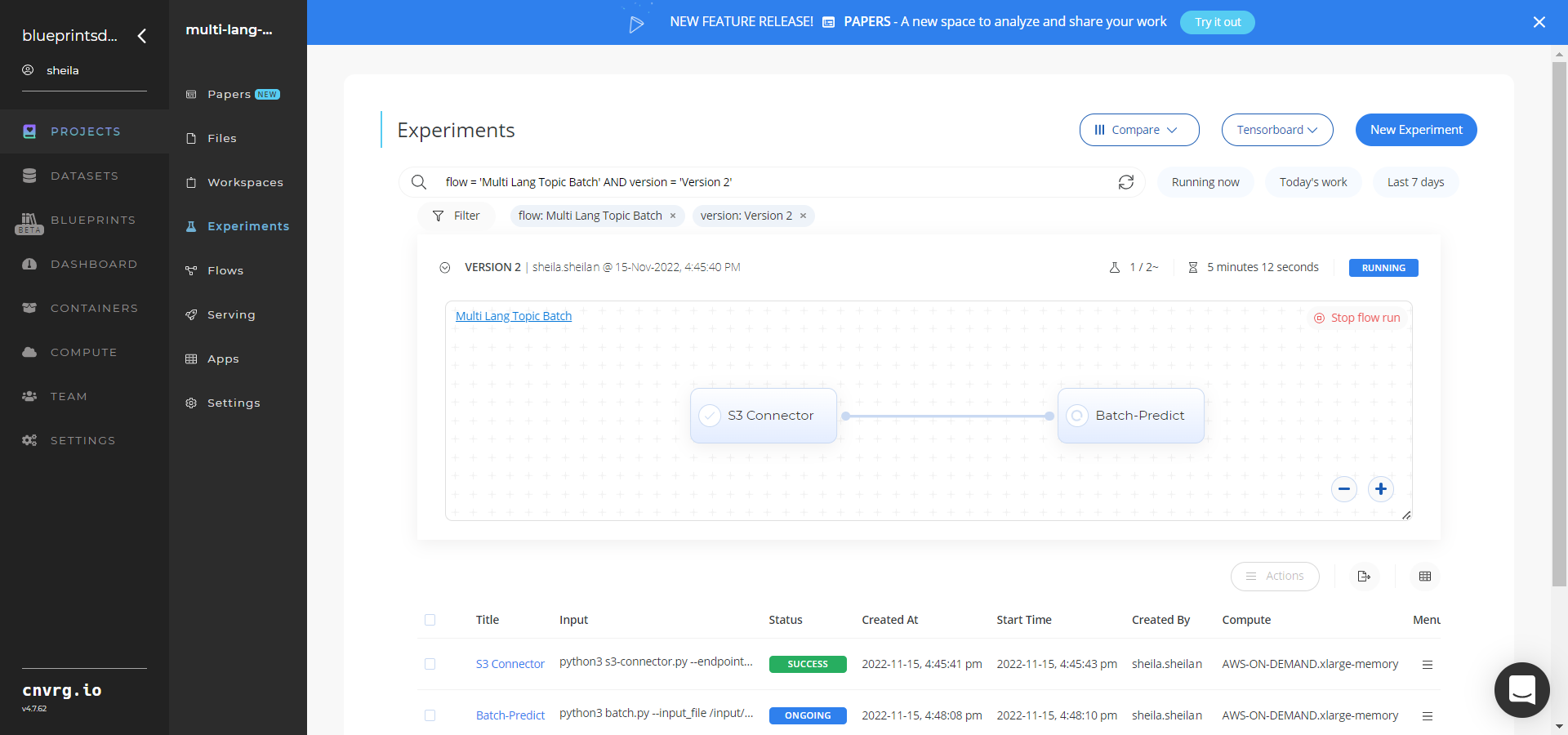
Select Batch Predict > Experiments > Artifacts and locate the batch output CSV files.
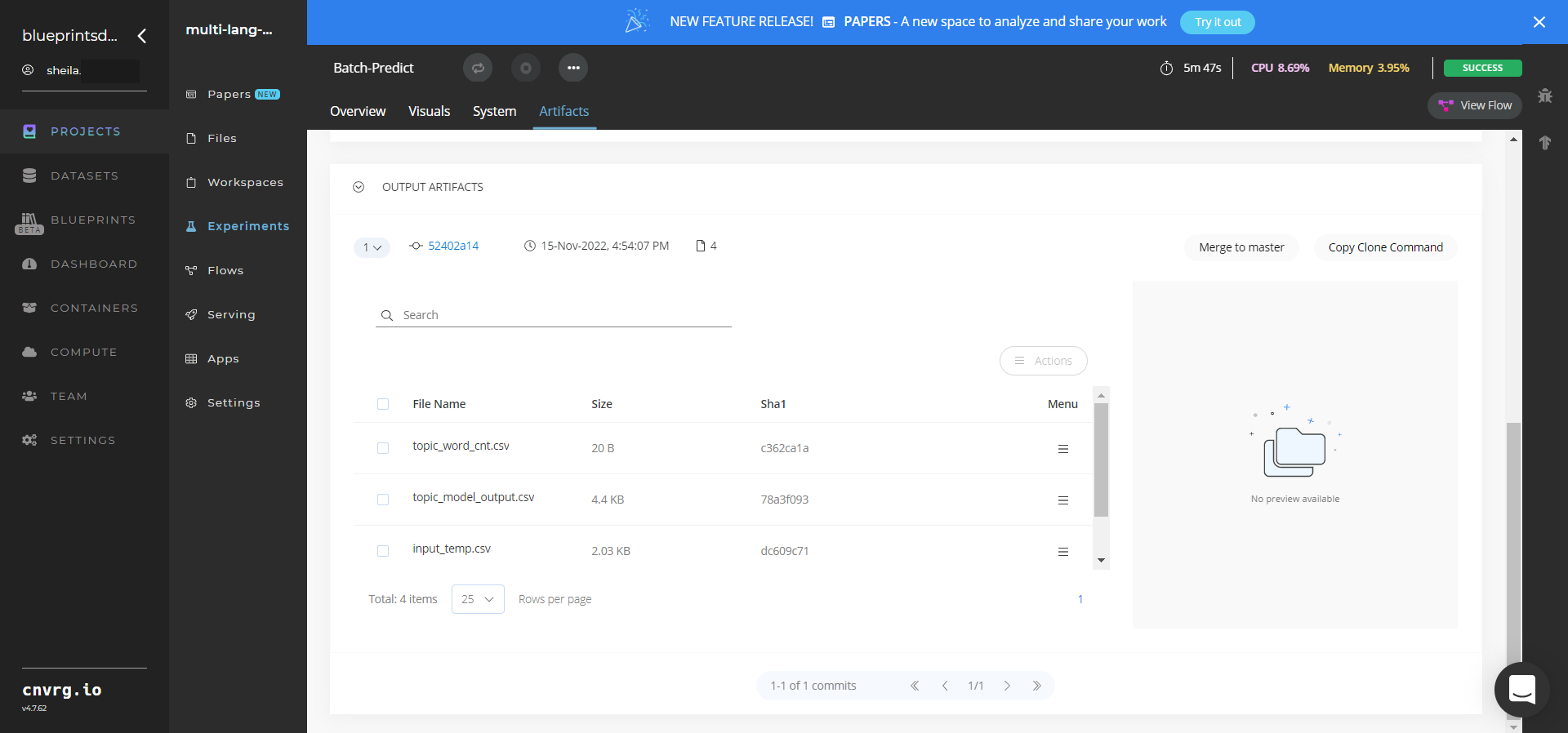
Click the topic_model_output.csv File Name, click the Menu icon, and select Open File to view the output CSV file.
A custom pretrained model that predicts topics from multi-language textual data has now been deployed in batch mode. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
# Related Blueprints
Refer to the following blueprints related to this batch blueprint:
- Multi-Language Topic Modeling Train
- Topic Modeling Inference
- Topic Modeling Train
- Topic Modeling Batch
- Text Summarization Training
- Text Summarization Batch
- Text Summarization Inference
# Training
Topic modeling uses a trained model to analyze and classify textual data and organize similar words and phrases over a set of paragraphs or documents to identify related text chunks or topics. The model can also be trained to determine whether text is relevant to the identified topics. Topic modeling models scan large amounts of text, locate word and phrase patterns, and cluster similar words, related expressions, and abstract topics that best represent the textual data.
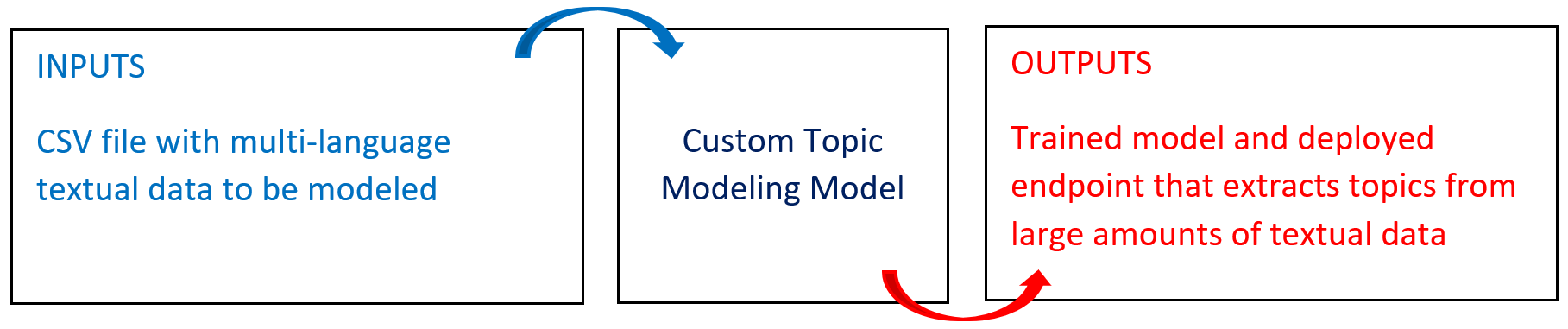
# Overview
The following diagram provides an overview of this blueprint’s inputs and outputs.
# Purpose
Use this training blueprint with multi-language data to train a topic model that extracts key topics out of a paragraph or document. The blueprint can be run with either your custom data or a random sample of Wikipedia articles as the training data.
To train this model with your data, create a folder in the S3 Connector that contains the multi_lang_modeling file, which stores the text to be decomposed (modeled). Also, provide a list of topics to extract from Wikipedia, if desired.
This blueprint also establishes an endpoint that can be used to extract topics from multi-language textual data based on the newly trained model. To train a topic model on a single-language dataset, see Topic Model Train.
NOTE
This documentation uses the Wikipedia connection and subsequent extraction as an example. The users of this blueprint can select any source of text and input it to the S3 and Batch-Predict tasks.
# Deep Dive
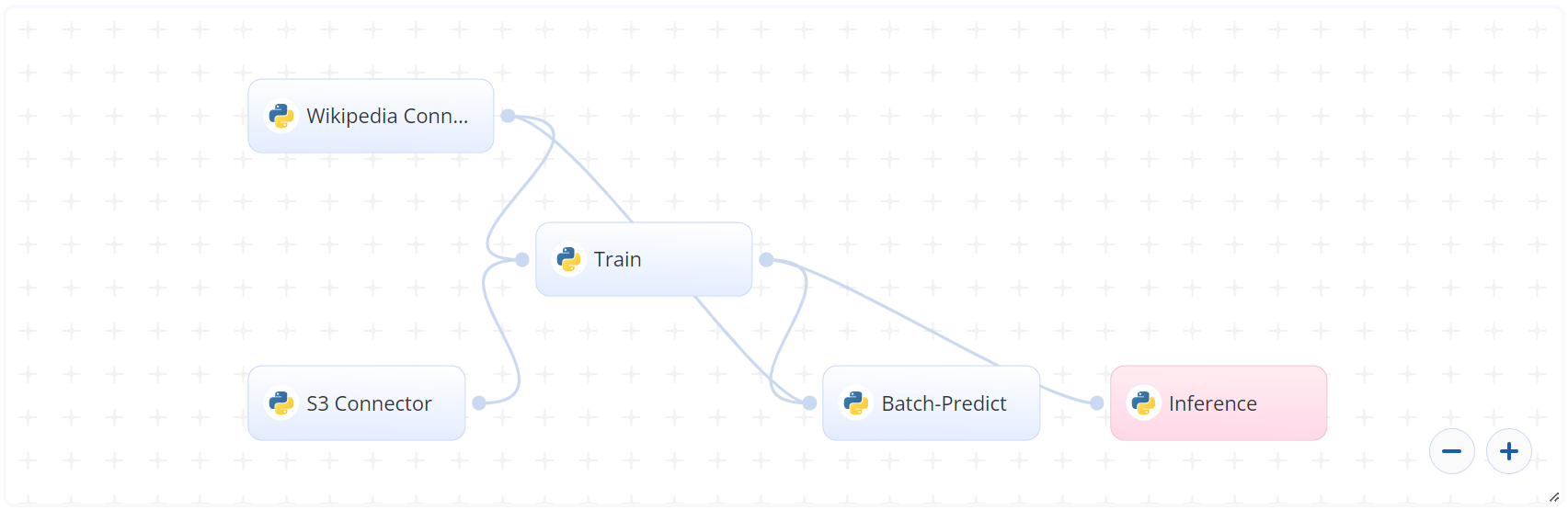
The following flow diagram illustrates this blueprint’s pipeline:
# Flow
The following list provides a high-level flow of this blueprint’s run:
- In the S3 Connector, the user provides the data bucket name and the directory path to the CSV file.
- In the Wikipedia Connector, the user provides a list of topics to extract from Wikipedia.
- In the Train task, the user provides the topic paths or CSV file path including the Wikipedia prefixes.
- In the Batch Predict task, the user provides path names to the CSV data file and the LDA model.
- The blueprint trains the model with the user-provided data to extract topics from textual data.
- The user uses the newly deployed endpoint to extract text topics using the newly trained model.
# Arguments/Artifacts
For more information on this blueprint’s tasks, its inputs, and outputs, click here.
# Wikipedia Inputs
--topics is a list of user-provided topics to extract from Wikipedia. Its format can be either comma-separated text or rows in a tabular-formatted CSV file named in this input argument. Default CSV format: /data/dataset_name/input_file.csv.
NOTE
Some topics are ambiguous in that a search for a keyword doesn’t yield a specific page. In that case, the first five of the disambiguation page values are circled through one by one.
# Wikipedia Outputs
--wiki_output.csv is the output file that contains the text in two-column CSV file format with the text in the first column and the corresponding title or topic in the second column.
# Train (LDA) Inputs
--training_fileis the name of the path of the directory storing the textual files that need to be modeled.--topic_sizeis a string of three comma-separated values of topic sizes on which to test the LDA algorithm. The minimum, maximum, and step size to increment the minimum value for testing. For example, 8,15,2 means the values tested are8,10,12,14. Recommended to use bigger step sizes for faster execution.--chunk_sizeis the number of documents to be used in each training chunk. For example, 100 means 100 documents are considered at a time. Default:100.--passesis the number of times the algorithm is to pass over the whole corpus. Default:1.--alphasets to an explicit user-defined array. It also supports special values of ‘asymmetric’ and ‘auto’, with the former using a fixed normalized asymmetric 1.0/topicno prior and the latter learning an asymmetric prior directly from your data. Default:symmetric.--etasets to an explicit user-defined array. It also supports special values of ‘asymmetric’ and ‘auto’, with the former using a fixed normalized asymmetric 1.0/topicno prior and the latter learning an asymmetric prior directly from your data. Default:symmetric.
# Train (LDA) Outputs
--topics_cnt_file.csvis a two-column (Topics_CountandCoherence) output file that contains the mapping of each topic count (such as 6,7,10) with a coherence score. It is sorted so the top count of topics is the one having the highest coherence score.
# Batch-Predict (LDA) Inputs
--input_fileis the name of the path of the directory storing the files needing decomposition.--model_fileis the path name to the saved LDA model file.--topic_word_cntis the count of words in each topic.--dictionary_pathis the path name to the saved tf-idf dictionary object.--model_results_pathis the path name to the results file that contains the number of topics (to be fed to the model) and their respective coherence scores.
# Batch-Predict (LDA) Outputs
--topic_model_output.csvis the output file that contains the mapping of each topic count (such as 6,7,10) with a coherence score. It is sorted so the top count of topics is the one having the highest coherence score.
# Instructions
NOTE
The minimum resource recommendations to run this blueprint are 3.5 CPU and 8 GB RAM.
Complete the following steps to train the topic-extractor model:
Click the Use Blueprint button. The cnvrg Blueprint Flow page displays.
In the flow, click the S3 Connector task to display its dialog.
- Within the Parameters tab, provide the following Key-Value pair information:
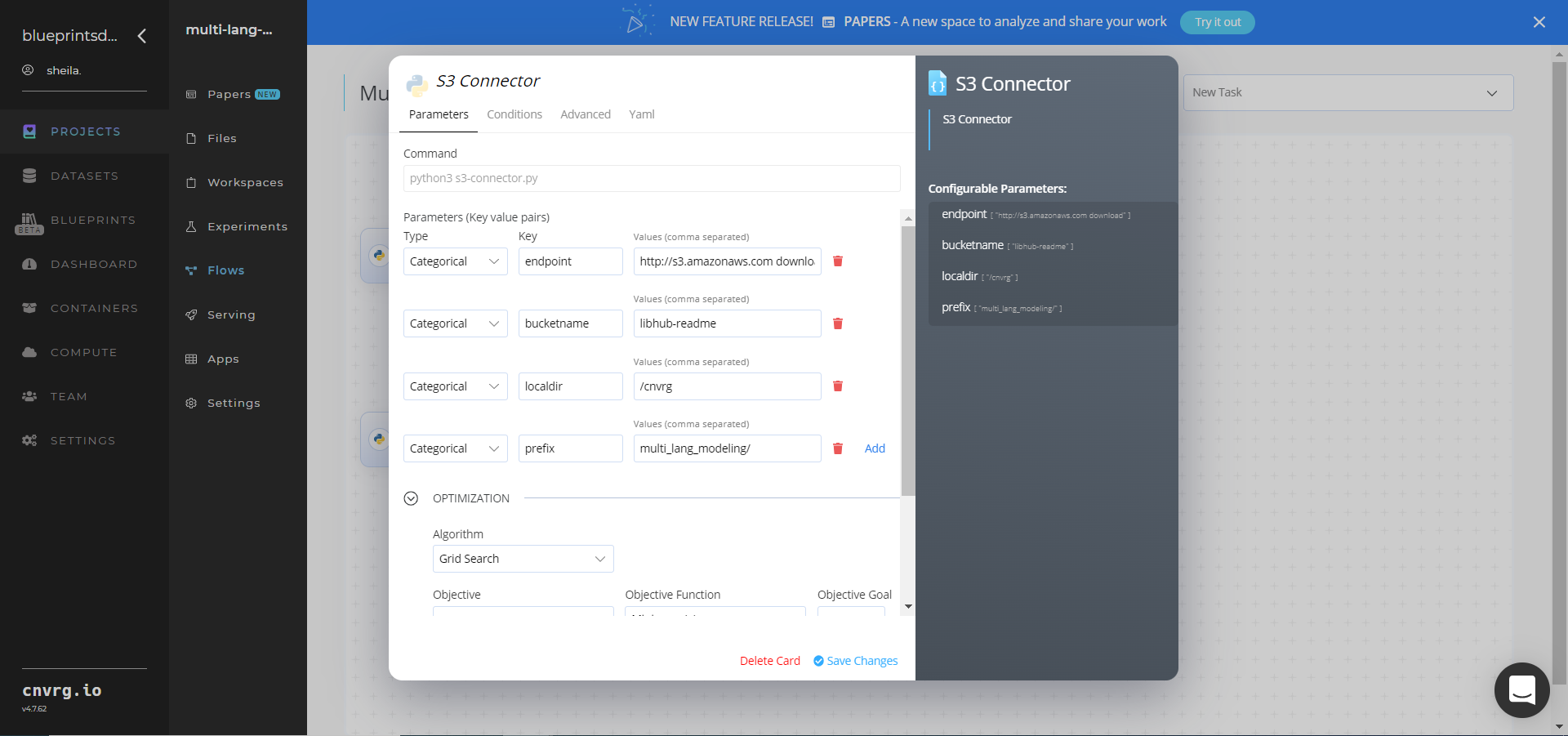
- Key:
bucketname− Value: enter the data bucket name - Key:
prefix− Value: provide the main path to the images folder
- Key:
- Click the Advanced tab to change resources to run the blueprint, as required.
- Within the Parameters tab, provide the following Key-Value pair information:
Click the Wikipedia Connector task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
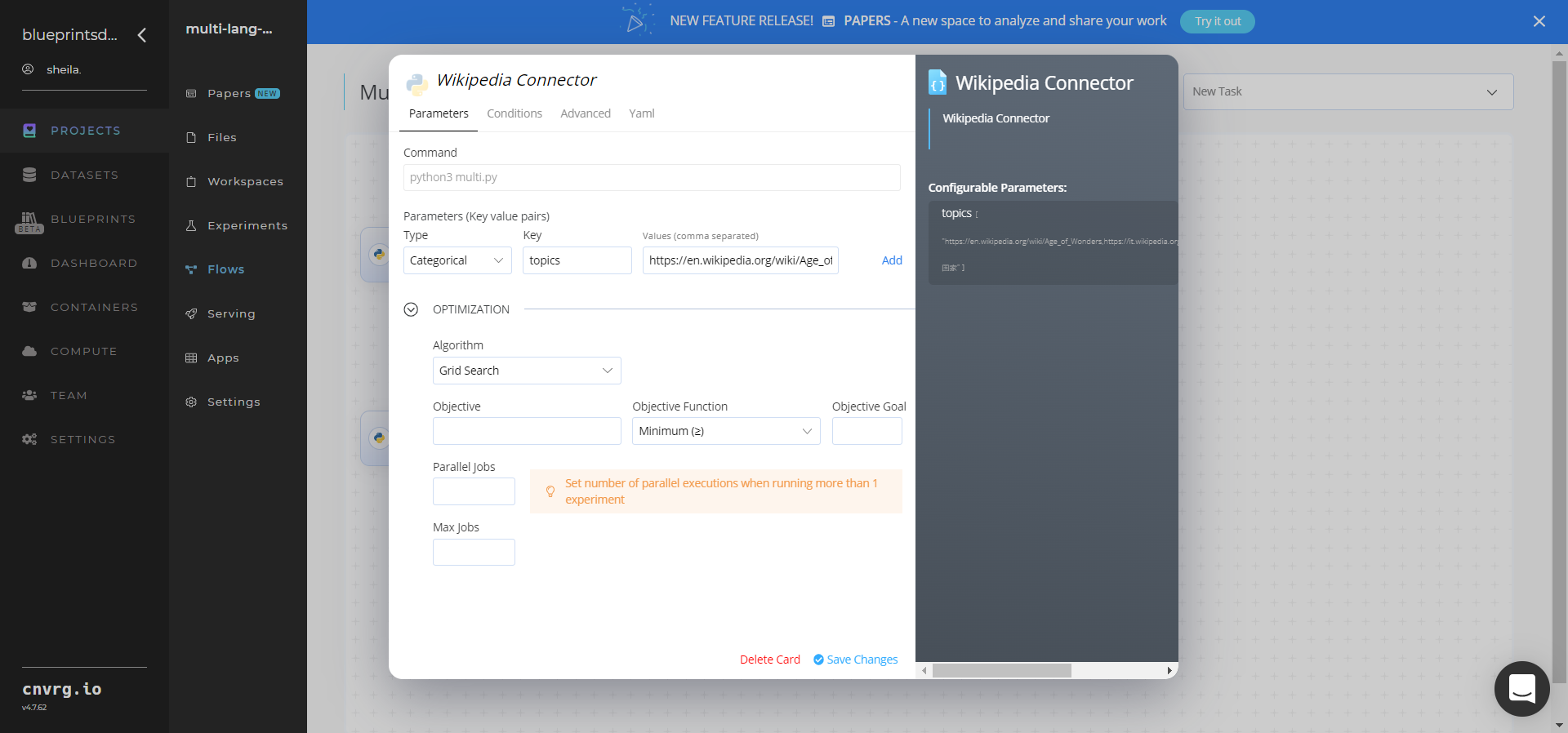
- Key:
--topics– Value: provide the list of topic paths to extract from Wikipedia in either comma-separated values or a CSV-formatted file https://en.wikipedia.org/wiki/Age_of_Wonders,https://it.wikipedia.org/wiki/Legge_Mammì,https://zh.wikipedia.org/wiki/国家– ensure the data input adheres to this example default format
NOTE
You can use the prebuilt example data path provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Return to the flow and click the Train (LDA) task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
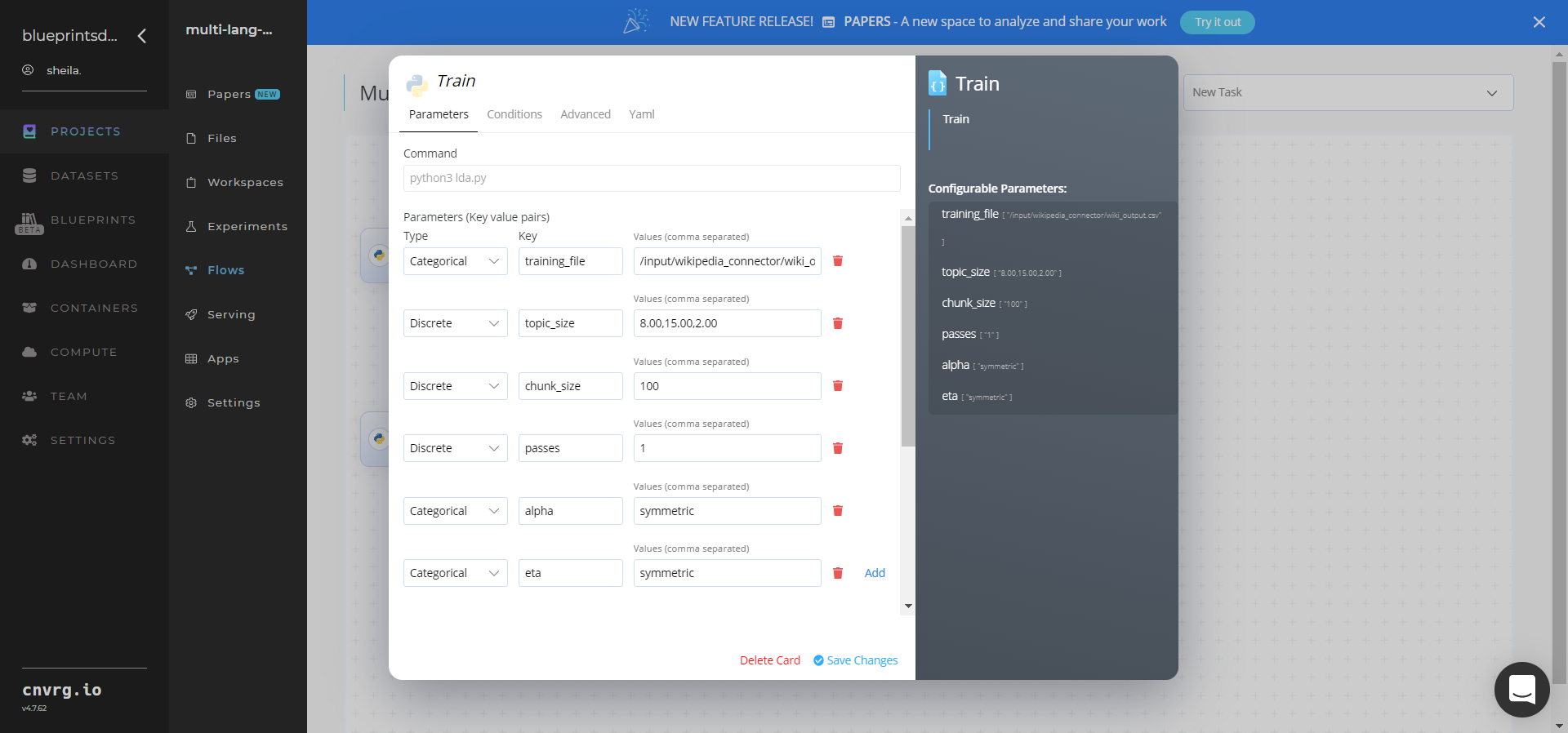
- Key:
--training_file– Value: provide the path to the CSV data file including the Wikipedia Connector prefix in the following format:/input/wikipedia_connector/wiki_output.csv - Key:
--topic_size– Value: provide the string of three comma separated values of topic sizes on which to test the LDA algorithm - Key:
--chunk_size– Value: enter the number of documents to be used in each training chunk - Key:
--passes– Value: set the number of times the algorithm is to pass over the corpus - Key:
--alpha– Value: set the explicit array - Key:
--eta– Value: set the explicit array
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the Batch-Predict (LDA) task to display its dialog.
Within the Parameters tab, provide the following Key-Value pair information:
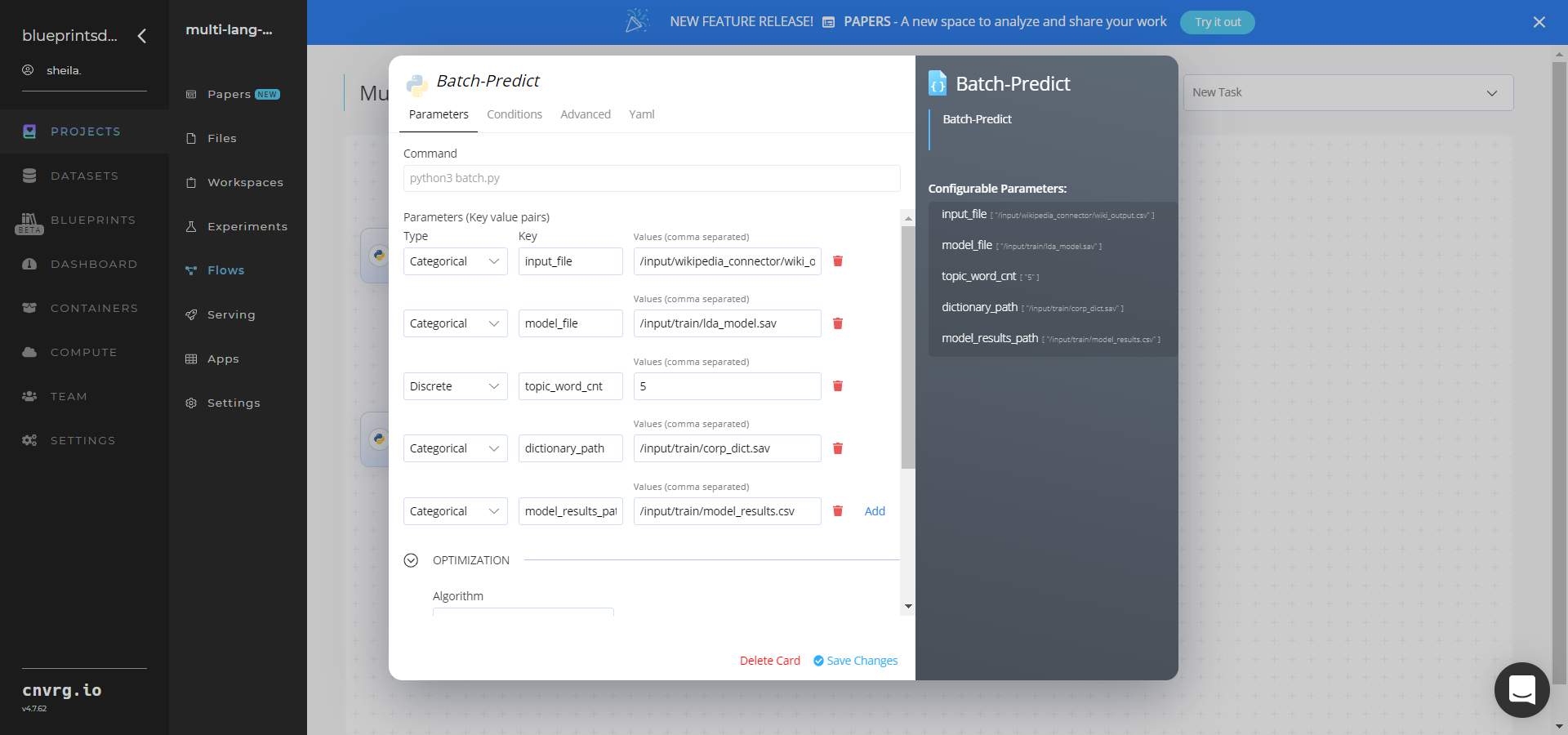
- Key:
--input_file– Value: provide the name of the directory path storing the CSV data file - Key:
--model_file– Value: provide the path name to the saved LDA model file - Key:
--topic_word_cnt– Value: provide the count of words in each topic - Key:
--dictionary_path– Value: provide the saved tf-idf dictionary object - Key:
--model_results_path– Value: provide the results file path that contains the number of topics
NOTE
You can use the prebuilt example data paths provided.
- Key:
Click the Advanced tab to change resources to run the blueprint, as required.
Click the Run button.
 The cnvrg software launches the training blueprint as set of experiments, generating a trained topic-extractor model and deploying it as a new API endpoint.
The cnvrg software launches the training blueprint as set of experiments, generating a trained topic-extractor model and deploying it as a new API endpoint.NOTE
The time required for model training and endpoint deployment depends on the size of the training data, the compute resources, and the training parameters.
For more information on cnvrg endpoint deployment capability, see cnvrg Serving.
Track the blueprint's real-time progress in its Experiment page, which displays artifacts such as logs, metrics, hyperparameters, and algorithms.
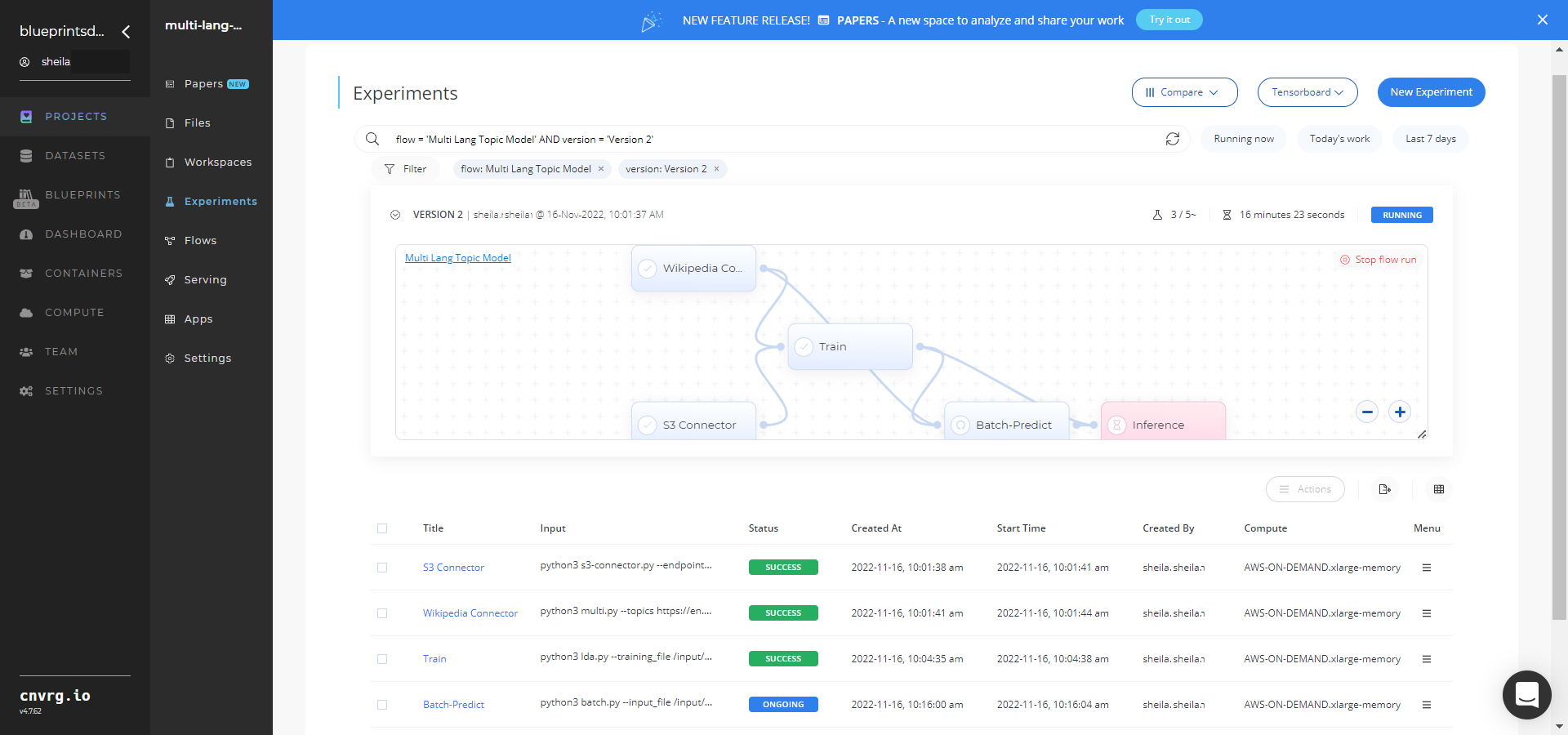
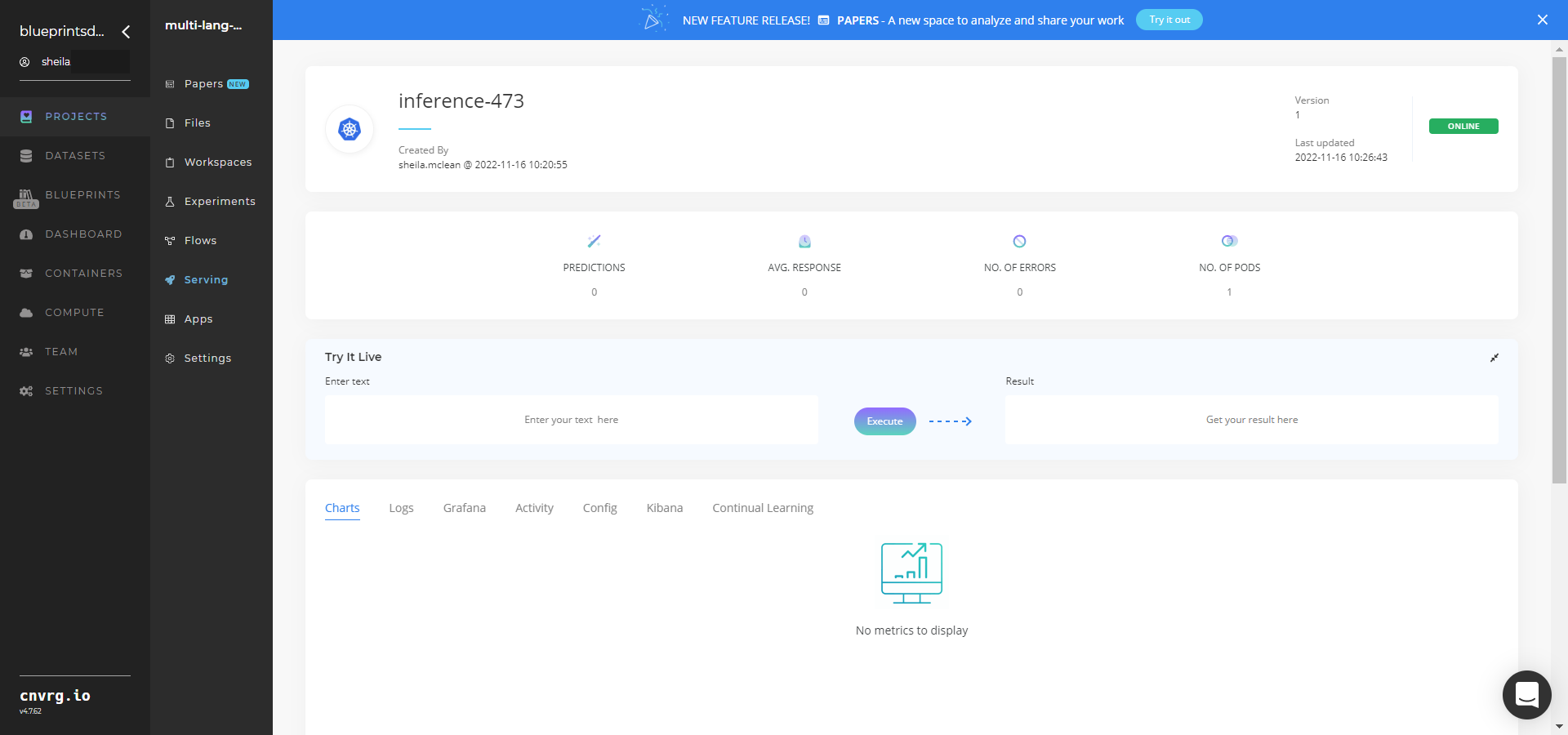
Click the Serving tab in the project and locate your endpoint.
Complete one or both of the following options:
- Use the Try it Live section with any text to check the model’s ability to summarize.
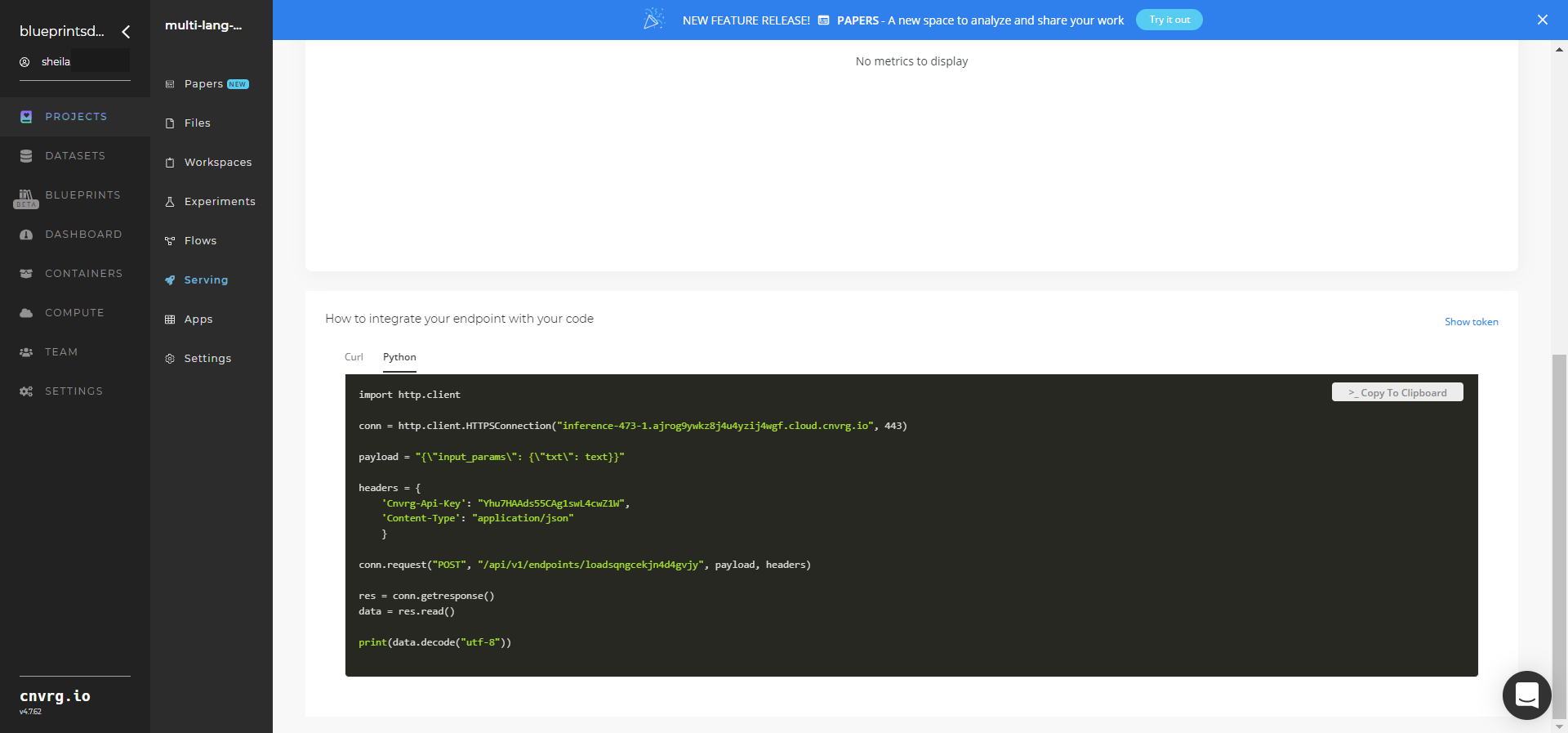
- Use the bottom integration panel to integrate your API with your code by copying in your code snippet.
- Use the Try it Live section with any text to check the model’s ability to summarize.
A custom model and an API endpoint, which can extract text topics, have now been trained and deployed. For information on this blueprint's software version and release details, click here.
# Connected Libraries
Refer to the following libraries connected to this blueprint:
- S3 Connector
- Wikipedia Connector
- Multi-Lang Topic Model Train (LDA)
- Multi-Lang Topic Model Batch (LDA)
- Multi-Lang Topic Model Inference
# Related Blueprints
Refer to the following blueprints related to this training blueprint: